An Introduction to Voice and Multimodal Interactions
RIDR: Request - Interpretation - Dialog & Logic - Response


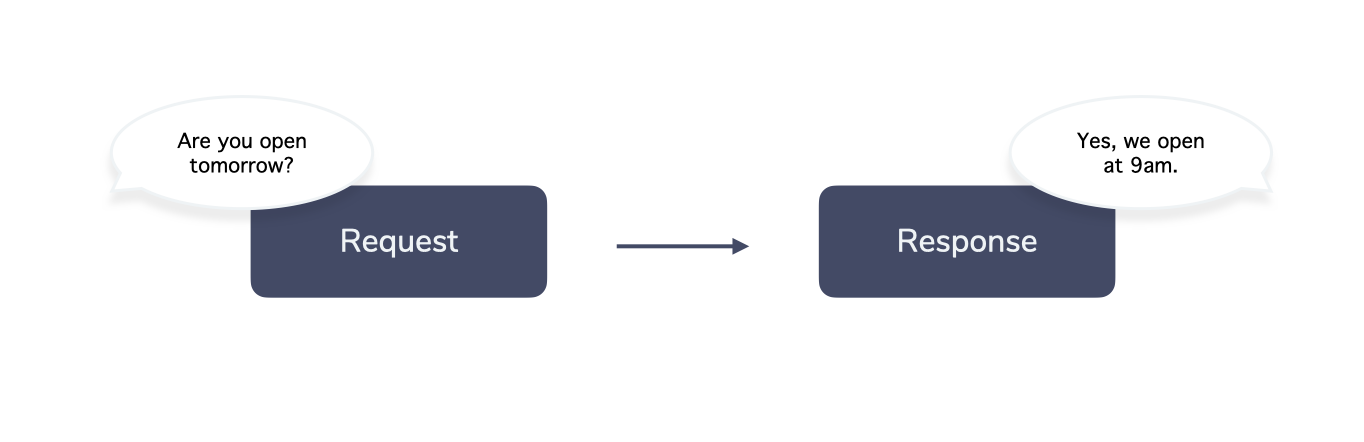
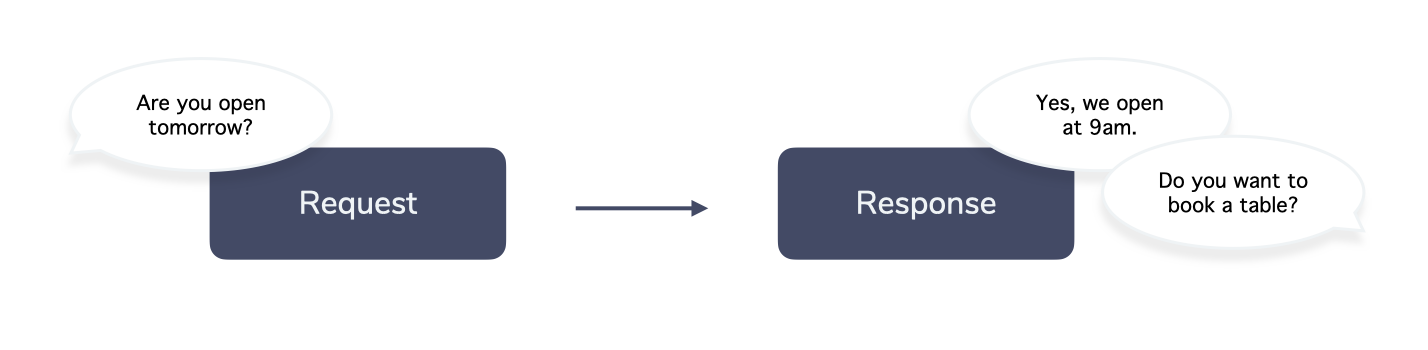
“Are you open tomorrow?”
“Yes, we open at 9am.”
The conversation above seems very simple, right? The goal of most voice and chat interactions is to provide a user experience that is as simple as possible. However, this doesn’t mean that these types of interactions are as easy to design or to build. Quite the contrary. There is a lot going on under the hood that the users never see (or, in this case, hear).
And it only becomes more complex as more modalities are added: With additional interfaces like visual and touch, maybe even gestures or sensory input, the design and development challenge can become multidimensional quickly. This is why it’s important to have a clear, abstracted process when building multimodal experiences.
In this post, I will walk you through some of the steps involved in building voice and multimodal interactions. We’ll take a look at the RIDR lifecycle, a concept that we introduced with the launch of Jovo v3 earlier this year.
To kick things off, let’s take a look at a typical voice interaction and then see how this can be expanded to multimodal experiences.
Example of a Voice Interaction

In the introduction of this post, a user asks a question (“Are you open tomorrow?”) and the system (e.g. a bot or an assistant) responds with a (hopefully appropriate) answer like “Yes, we open at 9am.”
This is what we call an interaction. In our definition, an interaction is a single pair of a user request and a system response.
What might appear like a simple interaction actually requires many steps under the hood to deliver a meaningful response. It looks more like this:
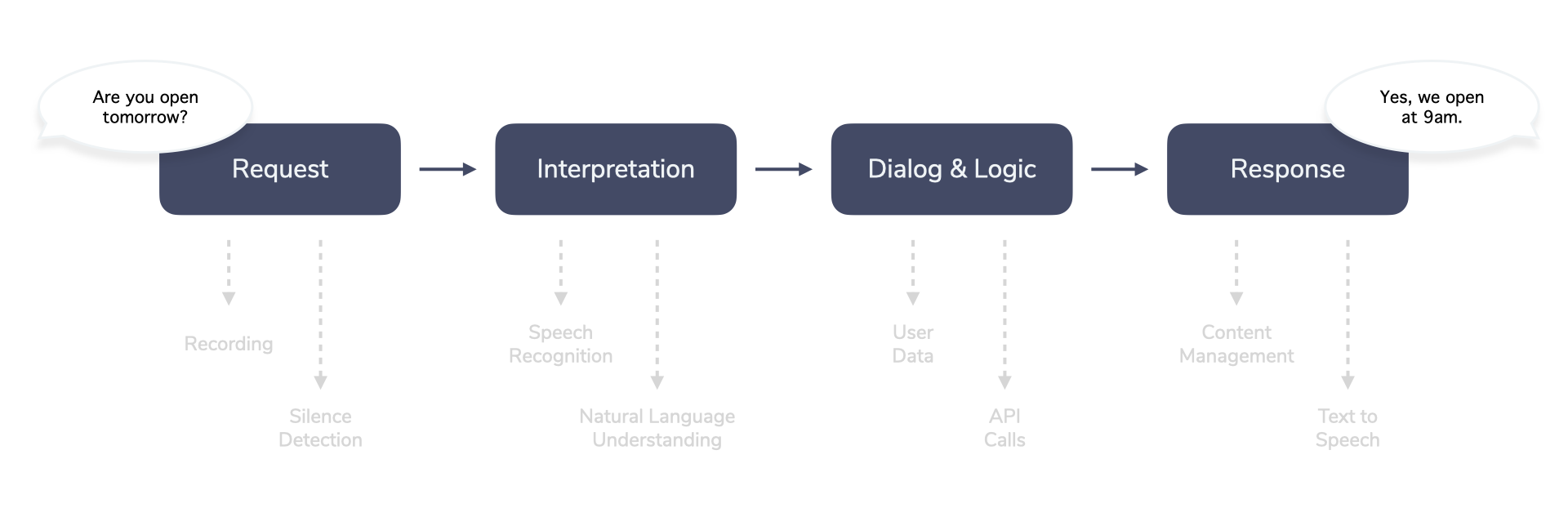
With the launch of Jovo v3, we introduced the RIDR (Request - Interpretation - Dialog & Logic - Response) lifecycle with the goal to establish an abstracted process to get from request to response and make it possible to plug into (interchangeable) building blocks for each step.
The pipeline includes four key elements:
- Request
- Interpretation
- Dialog & Logic
- Response
Let’s briefly take a look at each of the steps.
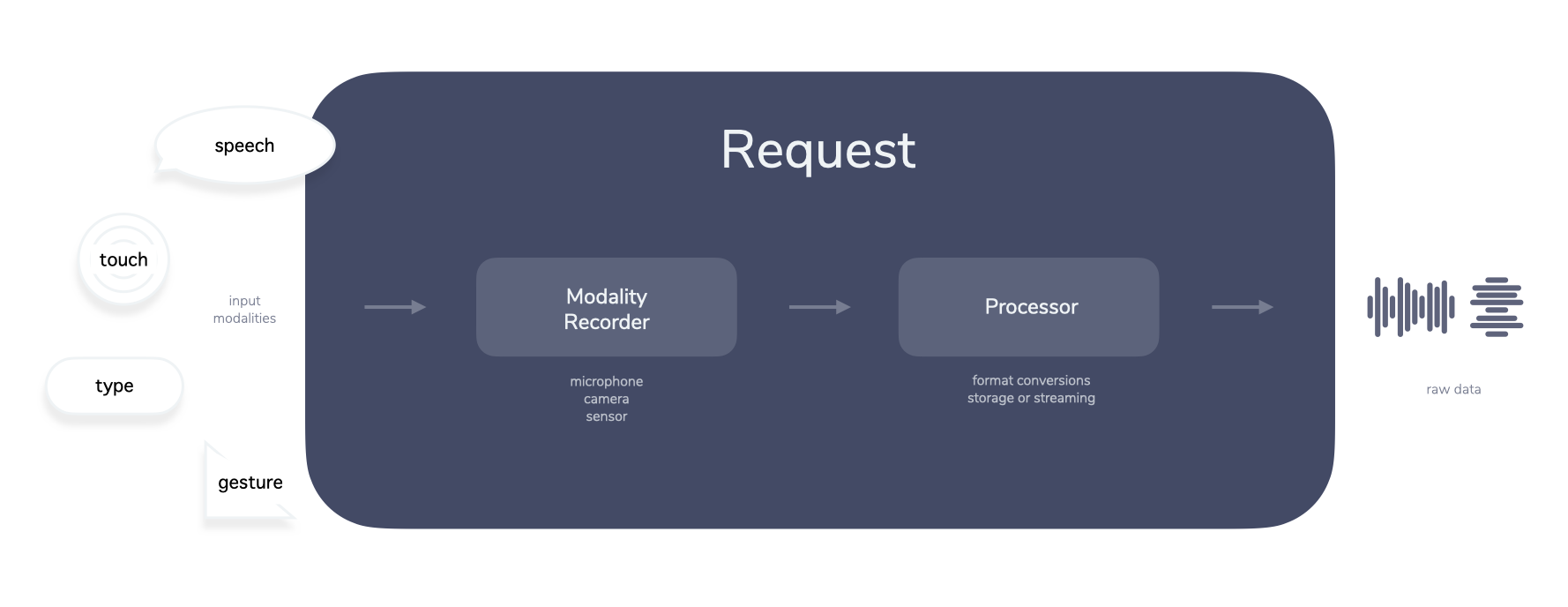
Request
The Request step starts the interaction and captures necessary data.
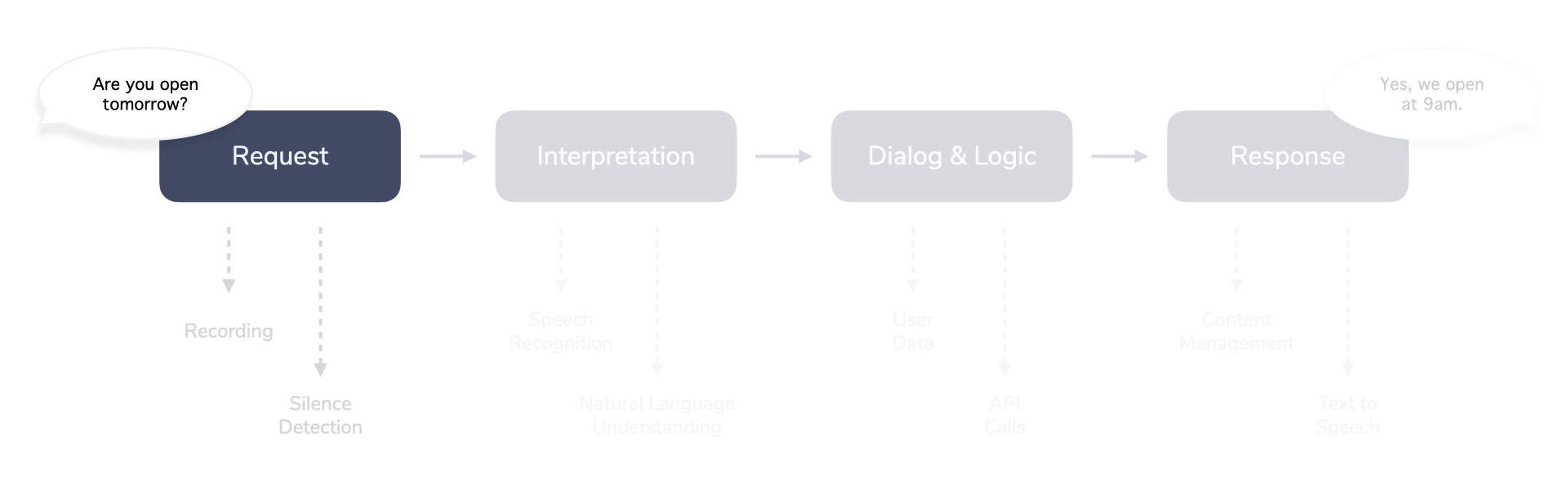
If we use a voice-first device as an example, there are a few things that need to be handled, like:
- Knowing when to record input (e.g. after a button is pushed or using wake word detection)
- Recording the input
- Figuring out when the person stopped speaking (e.g. with silence detection)
- Processing audio to be passed to the next step

These initial steps usually happen on the device the user is interacting with. Platforms like Amazon Alexa do all these things for you, but if you want to build your own custom voice system (e.g. voice-enabling a web or mobile app, building your own hardware), you may want to handle everything yourself. Jovo Client libraries like “Jovo for Web” help with some of these elements, like recording mechanisms, visual elements, silence detection, and audio conversions.
After the input is recorded, the request containing the audio is sent to the Interpretation step of the pipeline.
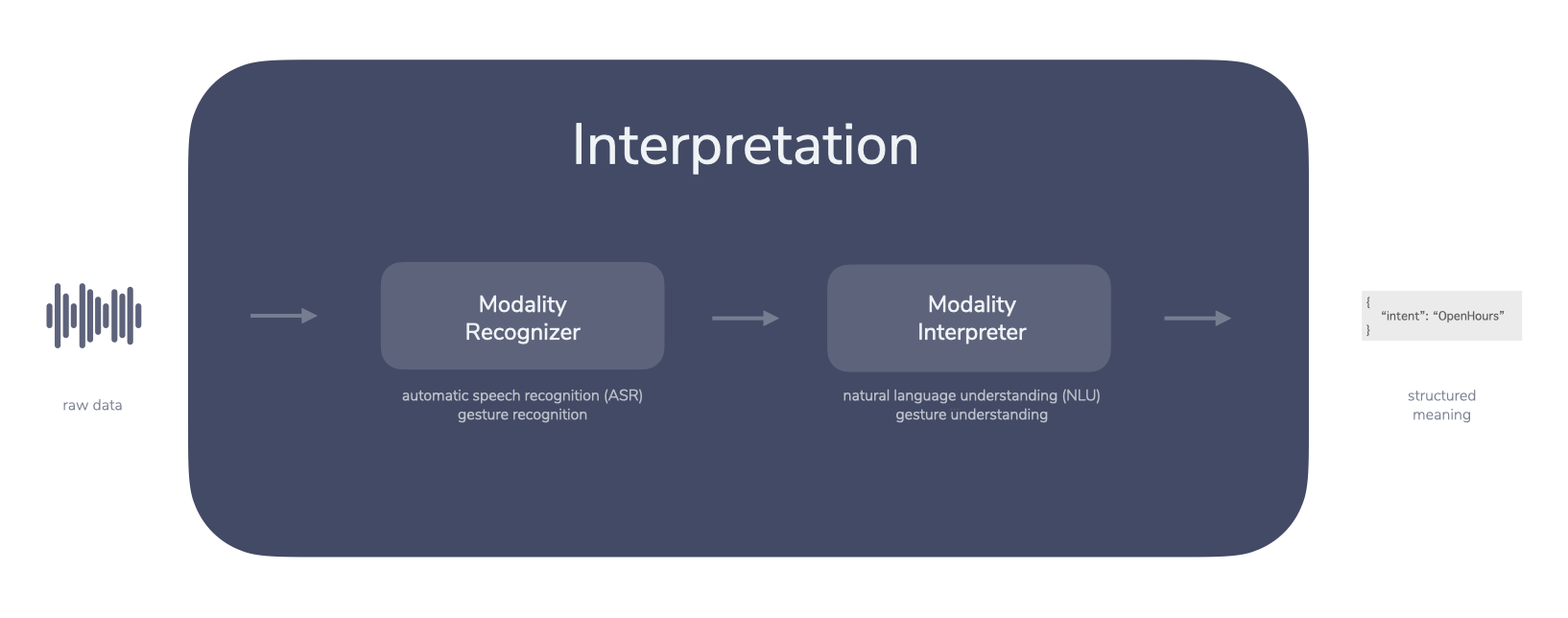
Interpretation
The Interpretation step tries to make sense of the data gathered from the Request.
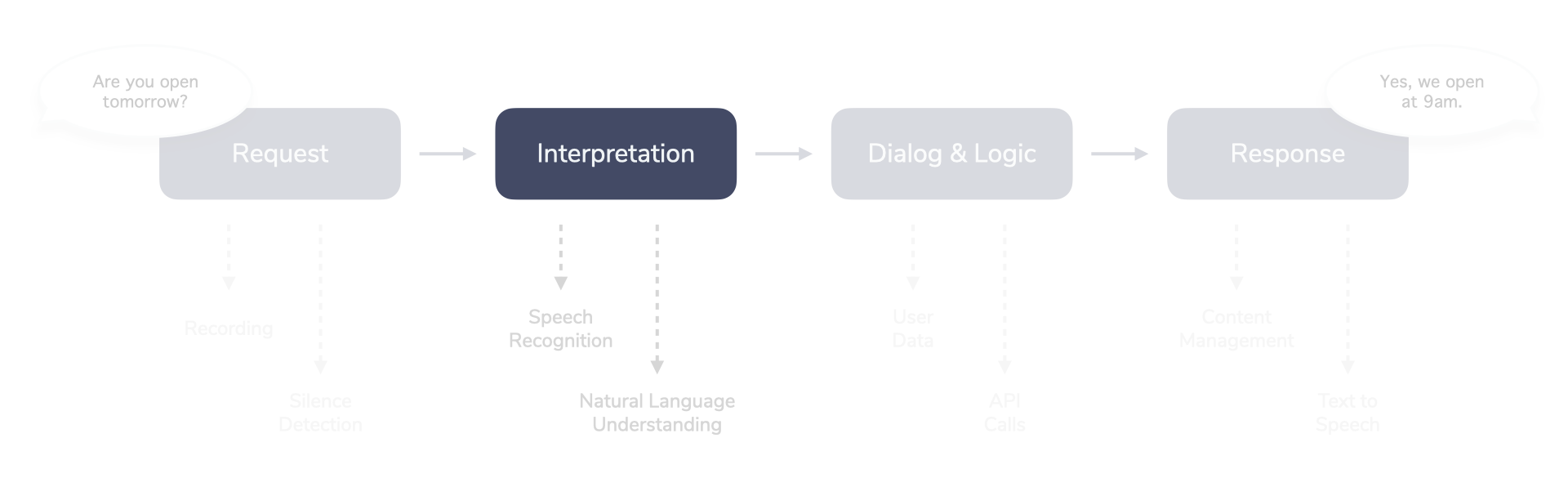
In our voice example, the previously recorded audio is now turned into structured meaning by going through multiple steps:
- An automated speech recognition (ASR) service turns the audio into text
- The text is then turned into a structure with intents and entities by a natural language understanding (NLU) service
- Additional steps could include speaker recognition, sentiment analysis, voice biometrics, and more
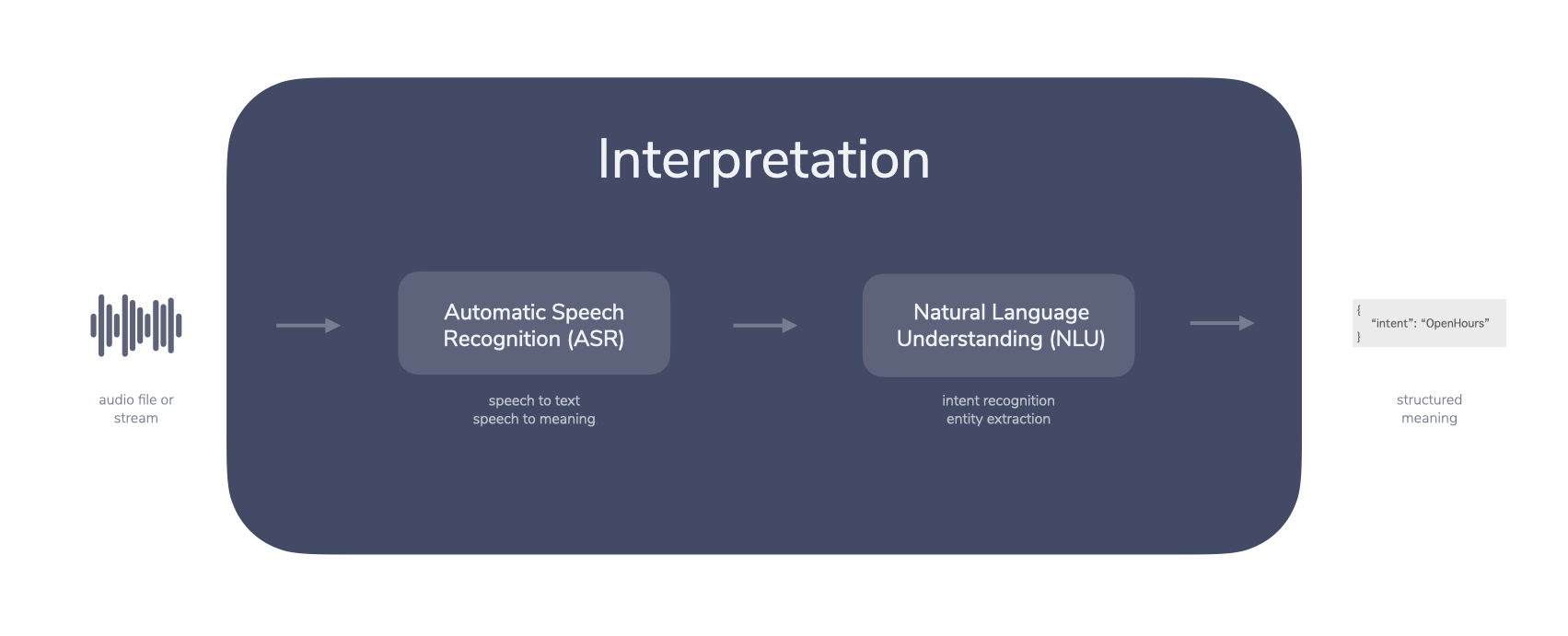
The Interpretation takes an audio file as input, runs it through various services, and then outputs structured, machine-readable data. This is usually a result of a natural language understanding (NLU) service that is trained with multiple phrases:
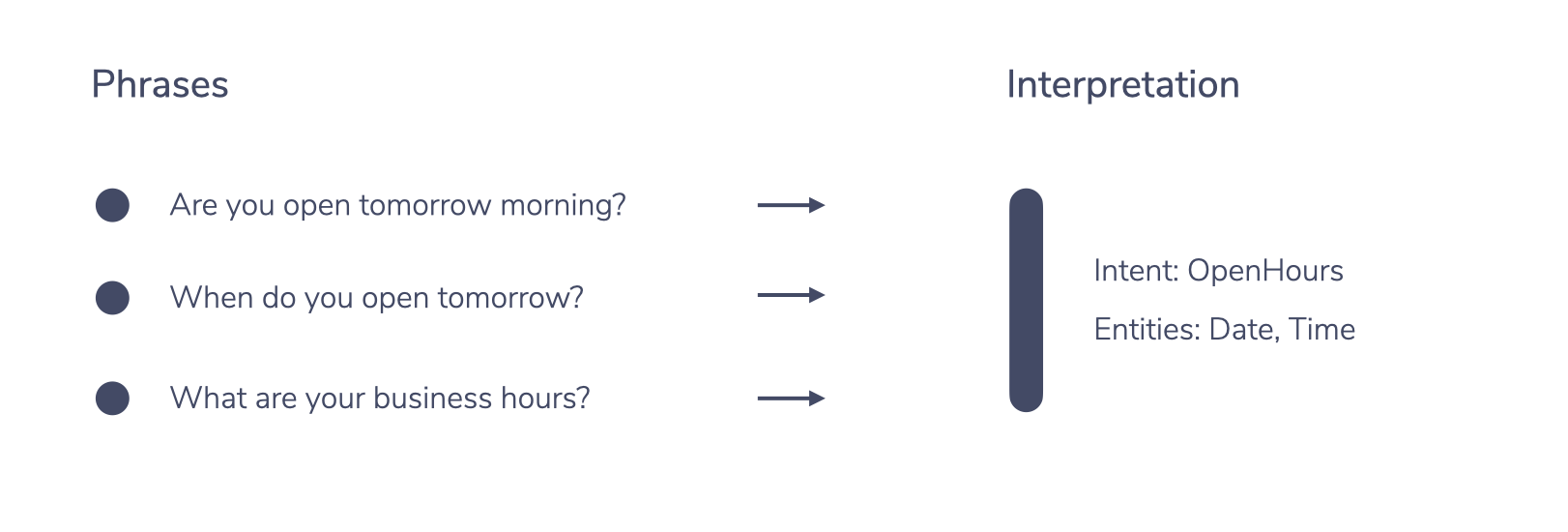
The service then matches the text provided by the ASR to an intent and optionally a set of entities. In our case it would be the OpenHours intent with additional information (“tomorrow”) in the form of an entity.
This structured data is then passed to the actual logic of the conversational app in Dialog & Logic.
Dialog & Logic
In the Dialog & Logic step it is determined how and what should be responded to the user.
This step involves a couple of important things such as:
- User Context: Is this a new or existing user? Is any additional data about them available, like preferred location?
- Dialog Management: Where in the conversation are we right now? Is there any additional input we need to collect from the user?
- Business Logic: Is there any specific information about the business that we need to collect?
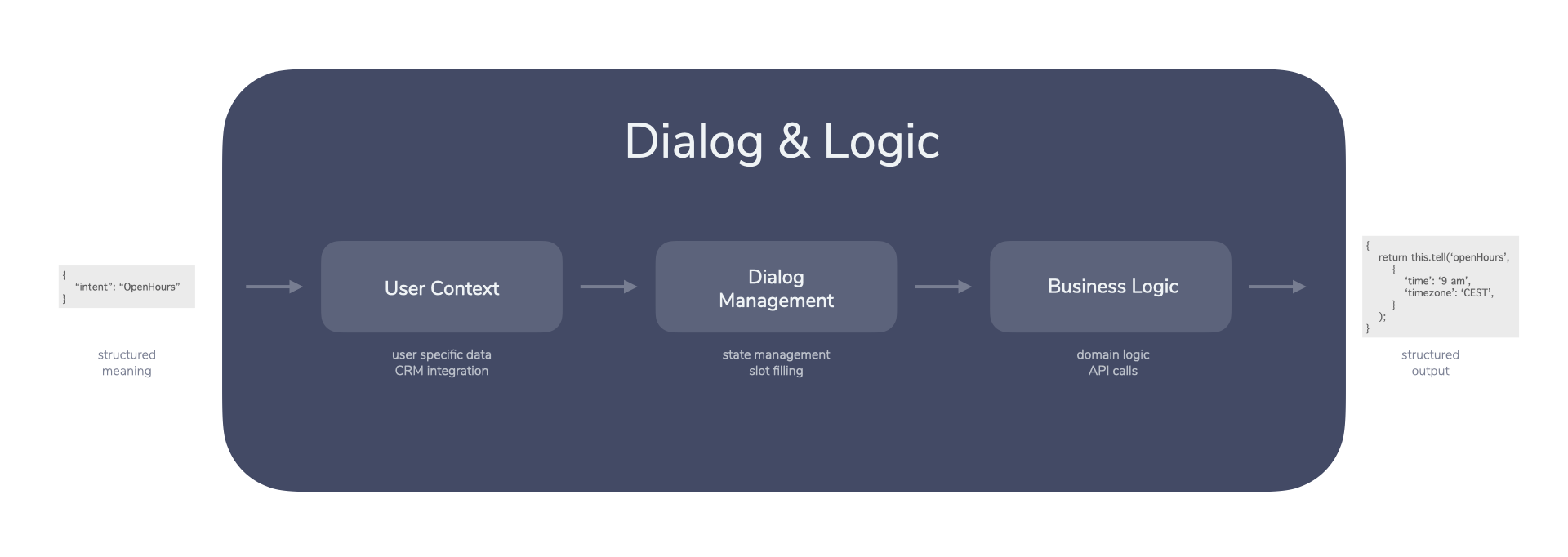
In the current example, we would collect data about opening hours, maybe specific to the user’s preferred location (if the system manages multiple locations).
All the necessary data is gathered and then handed off to the Response.
Response
In the final Response step, the data from the previous step is assembled into the appropriate output for the specific platform or device.
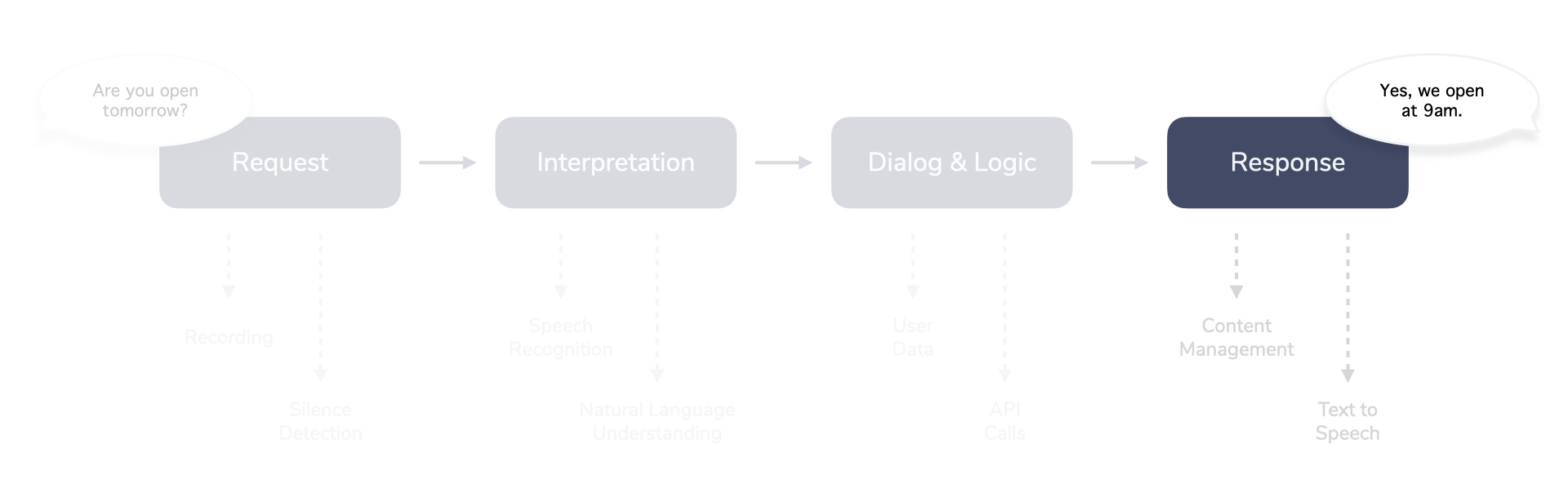
This also usually involves:
- Collecting data from a content management system (CMS) with e.g. localization features
- Sending the output to a text to speech (TTS) service that turns it into a synthesized voice

The output is then played back to the user, either stopping the session (closing the microphone) or waiting for additional input (a new Request). Rinse and repeat.
This example of a voice-only interaction still seems like a manageable process to design and build. What if we add more modalities though? Let’s take a look.
Multimodal Experiences Beyond Voice
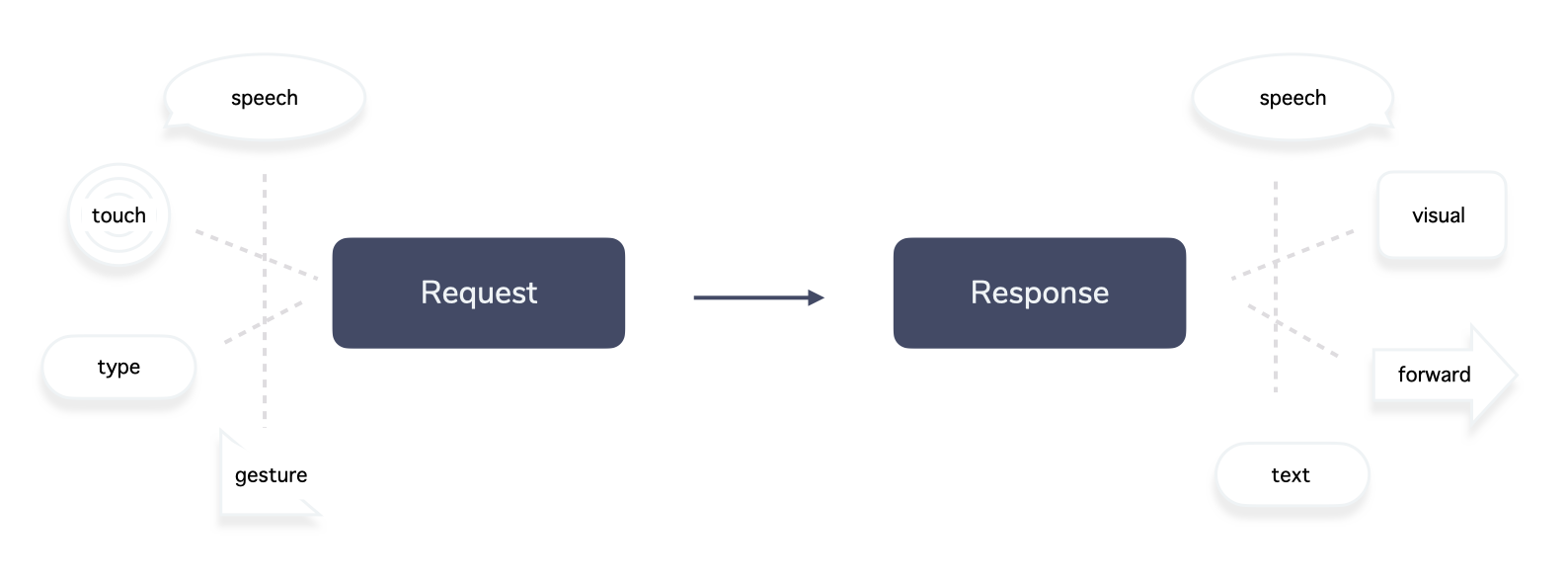
The previous example shows how RIDR works with a simple interaction that uses both speech input and output. Early voice applications for platforms like Amazon Alexa focused mainly on voice-only interactions, for example when people talk to a smart speaker without a display. (Note: You could argue that the LED light ring—which indicates that Alexa is listening—already makes it a multimodal interaction.)
As technology evolves, interactions between users and their devices are becoming increasingly complex. As I highlight in Introducing Context-First, products are becoming multimodal by default. This means that we’re seeing more interactions that either offer multiple input modalities (e.g. speech, touch, gestures) or output channels (e.g. speech, visual). Alexa, Please Send This To My Screen covers how multimodal interactions can either be continuous, complementary, or consistent experiences.
Let’s take a look at some multimodal experiences and how they could work with RIDR.
Examples of Multimodal Interactions
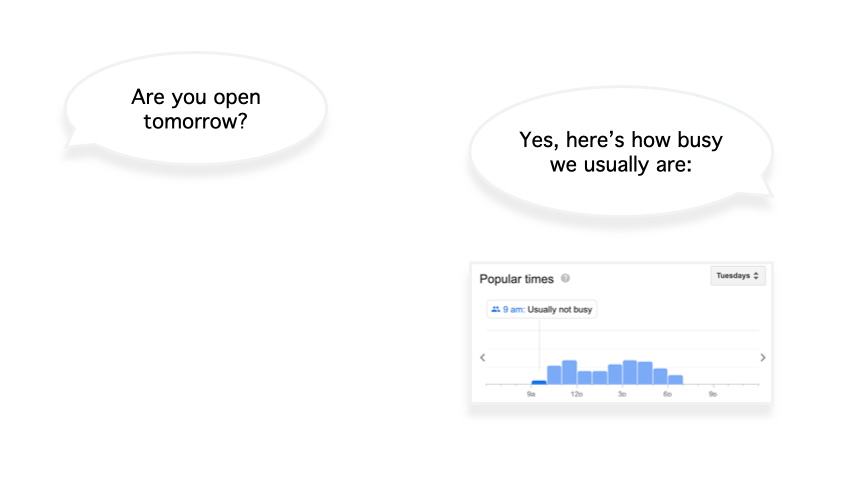
A multimodal experience could be as little as displaying additional (helpful) information on a nearby screen:
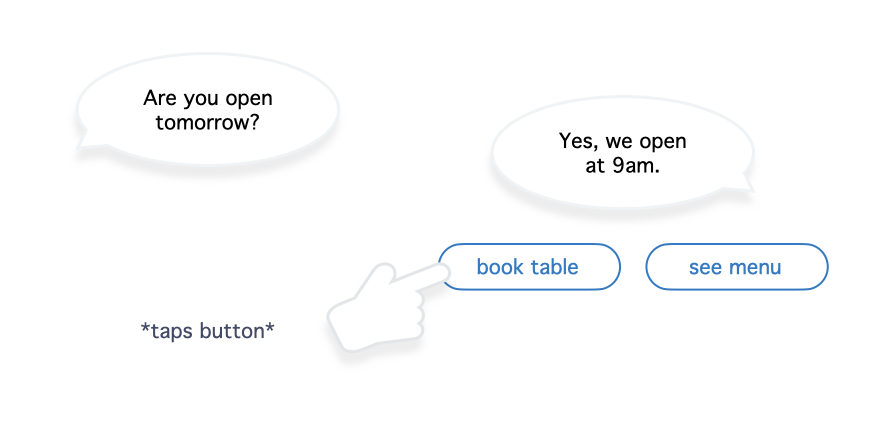
Or, the visual display could offer touch input for faster interactions, for example in the form of a button (they are sometimes called quick replies):
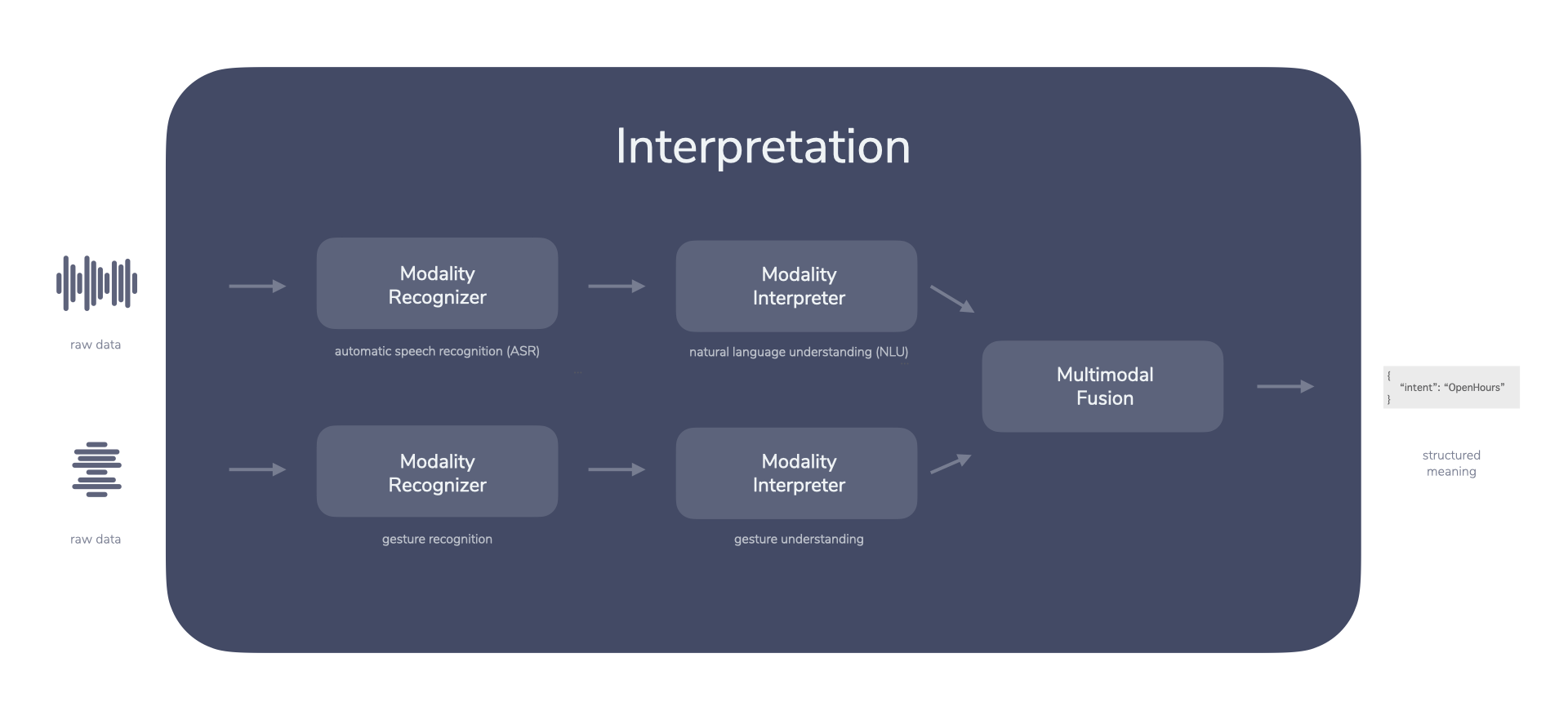
It gets increasingly interesting, and challenging to implement, when two input modalities are used in tandem:

The above is similar to Put That There which I mentioned in my previous post Introducing Context-First: Someone says something and provides additional context by pointing at an object. Interactions like this are challenging to decode and interpret. The process of making sense of multiple modalities is called multimodal fusion.
Multimodal Interactions and RIDR
Let’s take a look at how RIDR can be abstracted even more to work with multimodal interactions. The goal is that each of the building blocks can easily be replaced depending on the current context of the interaction.
For example, the Request step does not necessarily need to contain just a microphone, it could also have a camera or sensors to collect user input. We could call each of these elements a modality recorder.
In the Interpretation step, it could also be divided into two distinct steps. A recognizer that turns raw input (like audio, video, even emoji or a location) into a format that’s easier to process for an interpreter.
Not every interaction would need to go through each of the steps. Different input modalities might require different treatment:
- Text-based interactions (e.g. chatbots) can skip the speech recognition
- Touch-based interactions need to take into account the payload of e.g. a button (where was it clicked?)
- Vision-based interactions (e.g. gestures) need different steps that involve computer vision and interpretation
As mentioned earlier, this can get even more complex as you add multiple modalities at once. For this, an additional step for multimodal fusion is introduced.
The Dialog & Logic step from the voice example above can stay the same for now. We’ll take a deeper look at this in the next post as there are many additional layers to dive into.
The Response step is another interesting one. Where voice requires a text-to-speech (TTS) service, a multimodal experience might need additional elements like visual output or a video avatar. We call services fulfilling this step output renderers.

That’s how we currently envision multimodal user interfaces to work under the hood. This model will be updated and improved as we iteratively learn and experiment with the addition of new modalities.
Open Questions and Outlook
This post provided a first introduction to the many steps involved when building a seemingly simple voice interaction, and how this can be applied to multimodal experiences.
Again, this is a work in progress. Here are some additional questions I currently have:
- Right now, this only covers user-initiated (pull) request-response interactions. What if the system starts (push)? Could sensory data be used as a trigger?
- Should interpretation and dialog/logic be tied together more closely? How about dialog/logic and response? Rasa’s TED policy is one example where the interpretation step is doing some dialog and response work.
- Are there use cases where this abstraction doesn’t work at all? Do (currently still experimental) new models like GPT-3 work with this?
While this was already getting a bit complex at the second half of the article, it was still a simple example. It was a single response to a user request. What if we wanted to provide a follow-up question, like asking the user if they want to book a table?
There are many additional steps and challenges involved, especially in the Dialog & Logic step of the RIDR lifecycle. In the next post, I will provide an extensive introduction to dialogue management.
Finally! This post has been in the making for a while:
— Jan König (@einkoenig) September 21, 2020
✨ An Introduction to Voice and Multimodal Interactions ✨https://t.co/5hue7SgDaA #VoiceFirst #ContextFirst 1/x pic.twitter.com/ZqcydeOApe
Thanks a lot for your valuable feedback Dustin Coates, Julian Lehr, Braden Ream, Rafal Cymeris, Norbert Gocht, Alex Swetlow, and Lauren Golembiewski.
Photo by Jared Weiss on Unsplash.